
SSRF漏洞
SSRF漏洞
奇安信 渗透测试工程师Margin-51CTO SSRF系列文章:https://zhuanlan.zhihu.com/p/116039804
一、什么是SSRF漏洞
SSRF,Server-Side Request Forgery,服务端请求伪造,是一种由攻击者构造形成由服务器端发起请求的一个漏洞。一般情况下,SSRF 攻击的目标是从外网无法访问的内部系统。
漏洞形成的原因大多是因为服务端提供了向其他服务器应用请求获取数据的功能,但却没有对目标地址作过滤和限制。
攻击者可以利用 SSRF 实现的攻击主要有 5 种:
- 可以对外网、服务器所在内网、本地进行端口扫描,获取一些服务的 banner 信息
- 攻击运行在内网或本地的应用程序(比如溢出)
- 对内网 WEB 应用进行指纹识别,通过访问默认文件实现
- 攻击内外网的 web 应用,主要是使用 GET 参数就可以实现的攻击(比如 Struts2,sqli 等)
- 利用
file、gopher、dict协议读取本地文件、执行命令等
二、SSRF漏洞支持的协议
对于不同语言实现的web系统可以使用的协议也存在不同的差异,其中:
php:http、https、file、gopher、phar、dict、ftp、ssh、telnet…
java:http、https、file、ftp、jar、netdoc、mailto..
三、SSRF漏洞示例
1、假设一个漏洞场景:某网站有一个在线加载功能可以把指定的远程图片加载到本地,功
能链接如下:
wwW.xxX.comla.php?image=http://www.abc.com/1.jpg
那么网站请求的大概步骤应该是类似以下:
用户输入图片地址->请求发送到服务端解析->服务端请求链接地址的图片数据->获取请求
的数据加载到前台显示。
{kind=link}
我们可以利用这个漏洞进行攻击尝试:
1 | www.xxx.com?a.php?image=http://192.168.100.130:8080 |
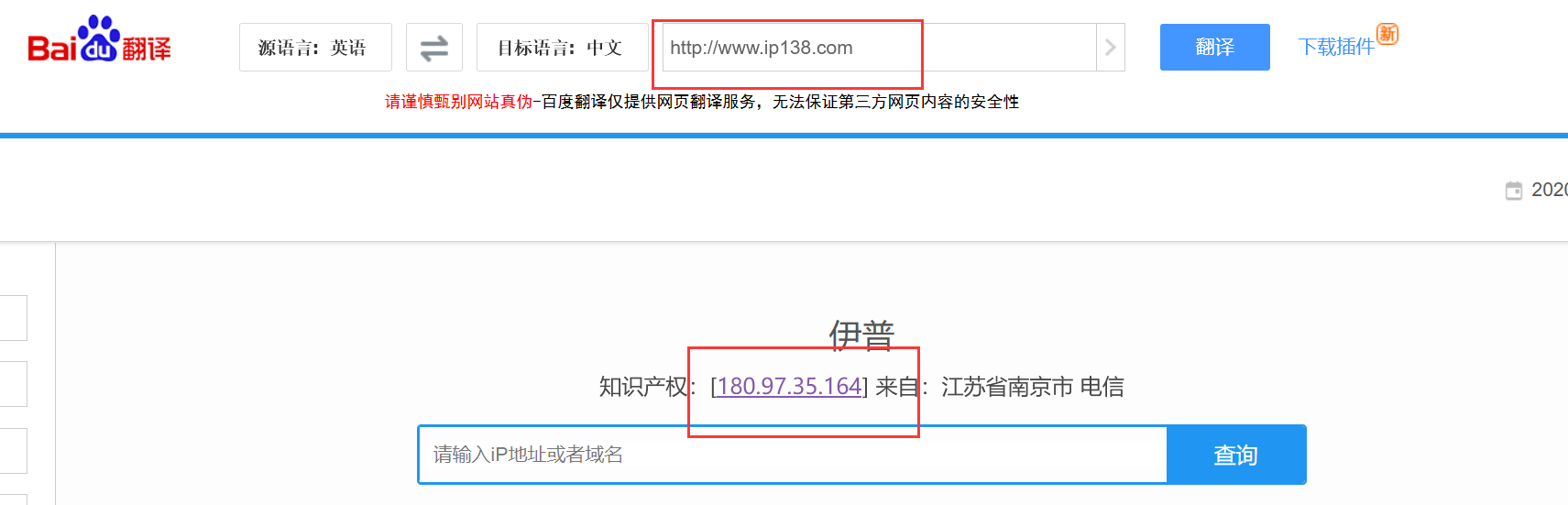
2、百度翻译这个网页执行了本身的翻译服务,而搜索IP也执行了他本身的搜索服务,这样
百度翻译就把自己的IP发送给www.ip138.com这个网址,IP翻译出来的结果就是百度翻译服务器所在的外网IP。
3、腾讯微博应用http:/lshare.xx.x.qq.com SSRF利用点,参数: url
http://share.xx.x.qq.com/index.php?c=share&a=pageinfo&url=http://wuyun.org
请求远程服务器的22端口,直接回显OpenSSH的banner信息
1 | #Payload |
四、SSRF漏洞常见场景
1、通过URL地址加载或下载图片
http://image.xx.com/image.php?image=http://tupian.baidu.com/2.jpg
图片加载存在于很多的编辑器中,编辑器上传图片处,有的是加载远程图片到服务器内。还有一些采用了加载远程图片的形式,本地文章加载了设定好的远程图片服务器上的图片地址,如果没对加载的参数做限制可能造成SSRF。
2、转码服务网站
转码服务就是通过 URL 地址把原地址的网页内容调优。使用不同的设备直接浏览某些网页内容的时候会造成显示上面的不便,因此有些公司提供了转码功能。使其适合手机屏幕浏览。例如百度、腾讯、搜狗等公司都有提供在线转码服务。
其它、
网页采集、抓取的地方;上传头像的地方;一切要你输入网址的地方和可以输入ip的地方;从URL关键字中寻找:share、wap、url、link、src、source、target、u、3g、display、sourceURl、imageURL、domain……
五、SSRF漏洞相关函数和协议
1、函数使用不当会造成SSRF漏洞
fsockopen——打开一个网络连接或者一个Unix套接字连接
1 | fsockopen ( string $hostname [, int $port = -1 [, int &$errno [, string &$errstr [, float $timeout = ini_get("default_socket_timeout") ]]]] ) : resource |
file_get_contents —— 将整个文件读入一个字符串
1 | file_get_contents ( string $filename [, bool $use_include_path = false [, resource $context [, int $offset = -1 [, int $maxlen ]]]] ) : string |
curl_exec — 执行 cURL 会话
1、PHP版本>=5.3
2、开启extension=php_curl.dll
3、–wite-curlwrappers(编译PHP时用,此时不需要,可忽略
1 | curl_exec ( resource $ch ) : mixed |
cURL是一个利用URL语法在命令行下工作的文件传输工具。支持的协议非常多,不同的curl版本支持不同的协议。
2、协议
(1)file:在有回显的情况下,利用file协议可以读取任意文件内容。
(2)dict:泄露安装软件版本信息,查看端口,操作内网redis服务等等。
(3)gopher:gopher支持发出GET、POST请求:可以先截获get请求包和post请求包,再构造成符合gopher协议的请求。gopher协议是ssrf利用中一个最强大的协议(俗称万能协议)。
(4)http/s:探测内网主机存活
六、SSRF限制绕过
1、绕过白名单
可以尝试采用http基本身份认证的方式绕过,http://www.xxx.com@www.aaa.com,对于`@`符号,PHP中不同的函数有不同的处理。
2、绕过黑名单
①采用进制转换:
1 | (1)、8进制格式:0177.0.0.1 |
②借助xip.io的DNS通配符服务:
1 | 10.0.0.1.xip.io resolves to 10.0.0.1 |
③添加端口号绕过
采用添加端口号http://127.0.0.1:80
④绕过localhost限制
http://[::]:80/ >>> http://127.0.0.1
⑤点转化为句号
利用句号127。0。0。1 >>> 127.0.0.1
⑥使用短地址
短地址转换工具:https://tinyurl.com/、http://tool.chinaz.com/tools/dwz.aspx
⑦利用Enclosed alphanumerics
1 | ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ >>> example.com |
七、SSRF漏洞加固
- 禁止302跳转,或者每跳转一次都进行校验目的地址是否为内网地址或合法地址。
- 过滤返回信息,验证远程服务器对请求的返回结果,是否合法。
- 禁用高危协议,例如:gopher、dict、ftp、file等,只允许http/https
- 设置URL白名单或者限制内网IP
- 限制请求的端口为http的常用端口,或者根据业务需要治开放远程调用服务的端口
- catch错误信息,做统一错误信息,避免黑客通过错误信息判断端口对应的服务
八、Gopher协议基础
1、Gopher协议简介
定义:Gopher是Internet上一个非常有名的信息查找系统,它将Internet上的文件组织成某种索引,很方便地将用户从Internet的一处带到另一处。在WWW出现之前,Gopher是Internet上最主要的信息检索工具,Gopher站点也是最主要的站点,使用tcp70端口。但在WWW出现后,Gopher失去了昔日的辉煌。现在它基本过时,人们很少再使用它;
gopher协议支持发出GET、POST请求:可以先截获get请求包和post请求包,在构成符合gopher协议的请求。gopher协议是ssrf利用中最强大的协议
限制:gopher协议在各个编程语言中的使用限制


–wite-curlwrappers:运用curl工具打开url流
curl使用curl –version查看版本以及支持的协议
Gopher协议格式:URL:gopher://<host>:<port>/<gopher-path>_后接TCP数据流
gopher的默认端口是70
如果发起post请求,回车换行需要使用%0d%0a,如果多个参数,参数之间的&也需要进行URL编码
协议结尾也要有%0d%0a
2、Gopher的案例
①GET
1 | python -m HTTP.server #开启8080HTTP服务,且当前目录下有一个index.html |
②POST
1 | curl gopher://192.168.2.244:80/_POST%20/SSRF/gopherPOST.php%20HTTP/1.1%0d%0ahost:192.168.2.244%0d%0acontent-type:application/x-www-form-urlencoded%0d%0acontent-length:8%0d%0a%0d%0aname=zjc%0d%0a #向WIN7-PTE靶机下一个接收并打印POSTname参数的php资源发送POST请求。 |
九、利用SSRF漏洞使用Gopher协议攻击Redis获得Shell
0x00 Redis基础
1、Redis定义
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统。
Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Hash), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。 —-摘自runoob
从哥抓包实际实验来看,gopher数据报文就是一个TCP+IP+MAC的报文,有数据应用层就直接加上数据
2、Redis安装
在开始之前建议先学习下Redis的基础知识:Redis基础知识,会事半功倍。
安装以Kali2.0为例,安装前需要更新源以及软件列表,参考链接:更改Kali源
安装如步骤如下:
①、安装redis
1 | apt-get install redis-server |
②、修改redis监听IP(如果不修改,不可远程登录),IP需要替换为自己的IP
1 | vim /etc/redis/redis.conf |
③、启动redis服务
1 | service redis-server start |
0x01 Redis入侵,反弹shell
在开始讲攻击Redis之前,必须要理解Redis的客户端和服务端的通信方式,以及数据发送的格式,该攻击的实现需要使用tcpdump的抓包功能。使用抓包软件来查看Redis客户端和Redis服务端的通信数据,找到语法结构后开始模拟客户端发送数据。
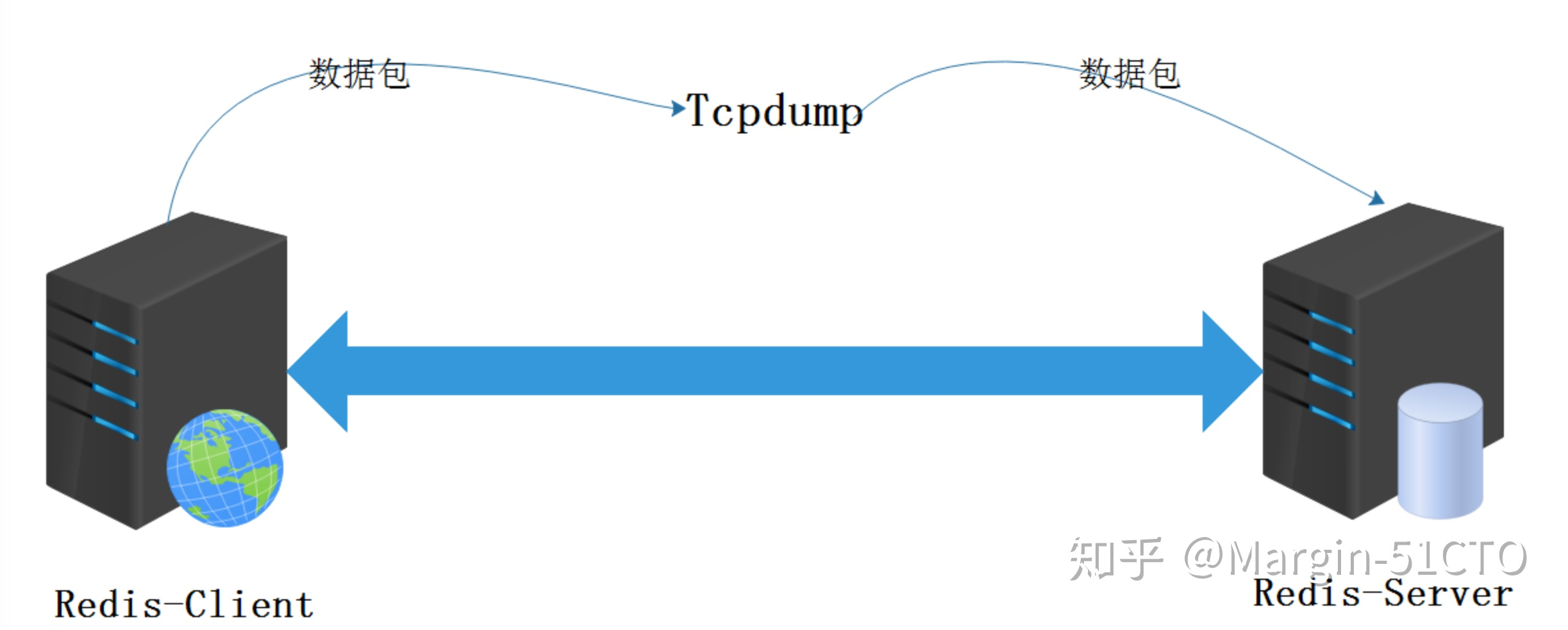
1、使用tcpdump来完成抓包,命令如下:
1 | tcpdump -i eth0 port 6379 -w redis.pcap |
2、使用Redis客户端登录Redis服务端,命令如下(默认无密码):
1 | root@Kali-2018:~/tmp# redis-cli -h 192.168.0.119 -p 6379 |
3、将抓到的pcap文件放到wireshark中分析
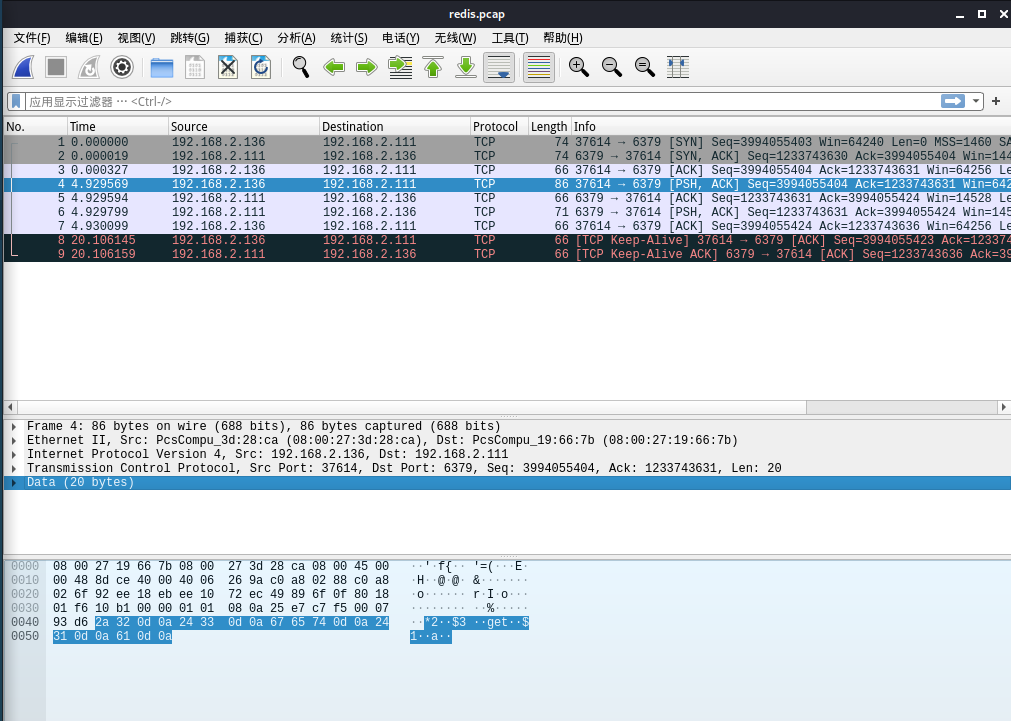
1 | 三次握手,两次数据交互和ACK,以及两次断开连接 |
如果不理解Redis的数据发送的数据包格式,是看不懂上面内容的,这里必须要讲这么几个内容:
3.1、序列化协议:客户端-服务端之间交互的是序列化后的协议数据。在Redis中,协议数据分为不同的类型,每种类型的数据均以CRLF(\r\n)结束,通过数据的首字符区分类型。
3.2、inline command:这类数据表示Redis命令,首字符为Redis命令的字符,格式为 str1 str2 str3 …。如:exists key1,命令和参数以空格分隔。
3.3、simple string:首字符为’+’,后续字符为string的内容,且该string 不能包含’\r’或者’\n’两个字符,最后以’\r\n’结束。如:’+OK\r\n’,表示”OK”,这个string数据。
3.4、bulk string:bulk string 首字符为’$’,紧跟着的是string数据的长度,’\r\n’后面是内容本身(包含’\r’、’\n’等特殊字符),最后以’\r\n’结束。如:
1 | "$12\r\nhello\r\nworld\r\n" |
上面字节串描述了 “hello\r\nworld” 的内容(中间有个换行)。对于” “空串和null,通过’$’ 之后的数字进行区分:
1 | "$0\r\n\r\n" 表示空串; |
3.5、integer:以 ‘:’ 开头,后面跟着整型内容,最后以’\r\n’结尾。如:”:13\r\n”,表示13的整数。
3.6、array:以’*‘开头,紧跟着数组的长度,”\r\n” 之后是每个元素的序列化数据。如:”*2\r\n+abc\r\n:9\r\n” 表示一个长度为2的数组:[“abc”, 9]。数组长度为0或 -1分别表示空数组或 null。
数组的元素本身也可以是数组,多级数组是树状结构,采用先序遍历的方式序列化。如:[[1, 2], [“abc”]],序列化为:”*2\r\n*2\r\n:1\r\n:2\r\n*1\r\n+abc\r\n”。
4、经过上面内容的讲解,在回过头理解抓到的redis的包就很容易明白了。
1 | 上面非常多的内容就不放了 |