
2、Http协议
Http协议
一、什么是Http协议
超文本传输协议(英文:HyperText Transfer Protocol,缩写:HTTP)HTTP 是一个在计算机世界里专门在「两点」之间「传输」文字、图片、音频、视频等「超文本」数据的「约定和规范」。
目前应用最广泛的Http协议是Http1.1
二、Http协议的特点
1、简单快速:向服务器发出请求,只需要提供请求方法和请求路径。请求方法常用的有GET、HEAD、POST。
HTTP 基本的报文格式就是 header + body,头部信息也是 key-value 简单文本的形式,易于理解,降低了学习和使用的门槛。
2、灵活:Http协议支持传输任何类型的数据对象。数据对象类型由Content-Type标记。
3、无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
4、无状态:Http协议是无状态协议,无状态是指Http协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重新来过。
无状态的好处,因为服务器不会去记忆 HTTP 的状态,所以不需要额外的资源来记录状态信息,这能减轻服务器的负担,能够把更多的 CPU 和内存用来对外提供服务。
无状态的坏处,既然服务器没有记忆能力,它在完成有关联性的操作时会非常麻烦。
例如登录->添加购物车->下单->结算->支付,这系列操作都要知道用户的身份才行。但服务器不知道这些请求是有关联的,每次都要问一遍身份信息。
对于无状态的问题,解法方案有很多种,其中比较简单的方式用 Cookie 技术。
Cookie通过在请求和响应报文中写入 Cookie 信息来控制客户端的状态。
5、长连接:早期 HTTP/1.0 性能上的一个很大的问题,那就是每发起一个请求,都要新建一次 TCP 连接(三次握手),而且是串行请求,做了无谓的 TCP 连接建立和断开,增加了通信开销。
为了解决上述 TCP 连接问题,HTTP/1.1 提出了长连接的通信方式,也叫持久连接。这种方式的好处在于减少了 TCP 连接的重复建立和断开所造成的额外开销,减轻了服务器端的负载。
持久连接的特点是,只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。
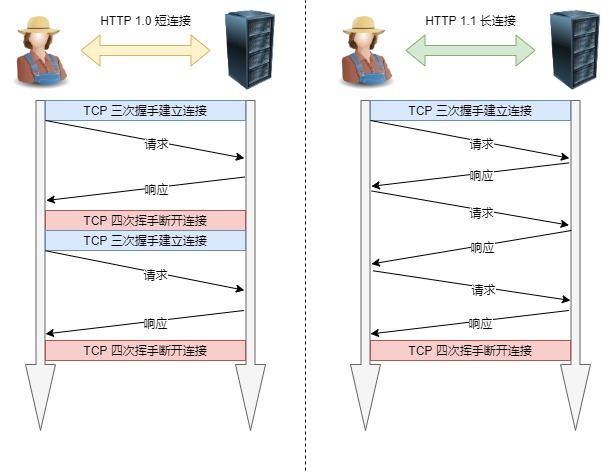
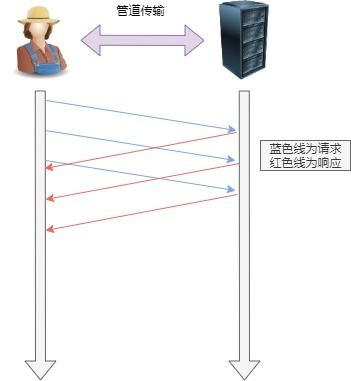
6、管道网络传输:HTTP/1.1 采用了长连接的方式,这使得管道(pipeline)网络传输成为了可能。即可在同一个 TCP 连接里面,客户端可以发起多个请求,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。
举例来说,客户端需要请求两个资源。以前的做法是,在同一个TCP连接里面,先发送 A 请求,然后等待服务器做出回应,收到后再发出 B 请求。管道机制则是允许浏览器同时发出 A 请求和 B 请求。但是服务器还是按照顺序,先回应 A 请求,完成后再回应 B 请求。要是前面的回应特别慢,后面就会有许多请求排队等着。这称为「队头堵塞」。
三、URL
1、URL: 统一资源定位器(Uniform Resource Locators)
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接,URL是一种特殊类型的URI。
1)URL格式:
1 | scheme://host.domain:port/path/filename?args#锚 |
- scheme - 定义因特网服务的类型。最常见的类型是 http(https/ftp/file)
- host - 定义域主机(http 的默认主机是 www)
- domain - 定义因特网域名,比如 runoob.com (host-domain可以是IP地址)
- :port - 定义主机上的端口号(http 的默认端口号是 80)
- path - 定义服务器上的路径(如果省略,则文档必须位于网站的根目录中)。
- filename - 定义文档/资源的名称
- args - 传入文档的参数
- 锚部分:从#到最后,定位页面
2)URL的字符编码:URL中只能用ASCII字符集,非ASCII字符集要经过编码,并且每字节编码前都要加%。(google浏览器显示URL中的汉字不会转换,但IE浏览器会转换为utf-8)。另外,URL 不能包含空格。URL 编码通常使用 + 来替换空格。
四、Http请求报文
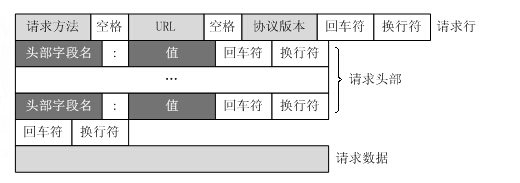
请求方法:Http1.1中定义9种方法:GET、POST、HEAD、OPTIONS、PUT、PATCH、DELETE、TRACE 、CONNECT
序号 方法 描述 1 GET 请求指定的页面信息,并返回实体主体。(get url最长1024) 2 HEAD 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 3 POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 4 PUT 从客户端向服务器传送的数据取代指定的文档的内容。 5 DELETE 请求服务器删除 Request-URI 所标识的资源。 6 CONNECT HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 7 OPTIONS 返回服务器针对特定资源所支持的HTTP请求方法。也可以利用向Web服务器发送’*’的请求来测试服务器的功能性,允许客户端查看服务器的性能。 8 TRACE 回显服务器收到的请求,主要用于测试或诊断。 9 PATCH 是对 PUT 方法的补充,用来对已知资源进行局部更新 。 虽然 HTTP 的请求方式有 8 种,但是我们在实际应用中常用的也就是 get 和 post,其他请求方式也都可以通过这两种方式间接的来实现。
头部字段:
Host:客户端发送请求时,用来指定服务器的域名。有了
Host字段,就可以将请求发往「同一台」服务器上的不同网站。User-Agent字段:用户使用的客户端的一些必要信息,如操作系统、浏览器以及版本、浏览器渲染引擎等。
X-forwarded-for:client, proxy1, proxy2 中间逗号隔开,表示客户端请求到达服务器之前经过了两个代理。
Client-IP:同上
Referer字段:该请求报文从哪个URL地址发送。
Connection 字段:
Connection字段最常用于客户端要求服务器使用 TCP 持久连接,以便其他请求复用。HTTP/1.1 版本的默认连接都是持久连接,但为了兼容老版本的 HTTP,需要指定Connection首部字段的值为Keep-Alive。一个可以复用的 TCP 连接就建立了,直到客户端或服务器主动关闭连接。但是,这不是标准字段。Accept字段:客户端请求的时候,可以使用
Accept字段声明自己可以接受哪些数据格式。Accept-Encoding字段:客户端在请求时,用
Accept-Encoding字段说明自己可以接受哪些压缩方法。Cookie字段:缓存数据。用户身份会话令牌,用于服务器标识客户端身份。
Content-Type:上传文件的MIME类型。
Destination:目标资源位置
五、Http响应报文
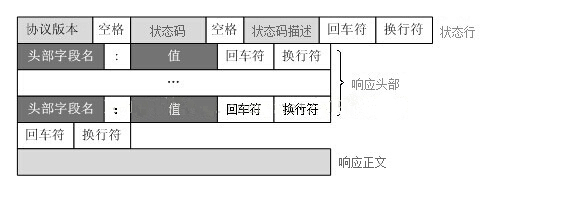
头部字段:
Server 字段:服务器类型。
Content-Length 字段:服务器在返回数据时,会有
Content-Length字段,表明本次回应的数据长度。Connection 字段:
Connection字段最常用于客户端要求服务器使用 TCP 持久连接,以便其他请求复用。HTTP/1.1 版本的默认连接都是持久连接,但为了兼容老版本的 HTTP,需要指定Connection首部字段的值为Keep-Alive。一个可以复用的 TCP 连接就建立了,直到客户端或服务器主动关闭连接。但是,这不是标准字段。Content-Type 字段:
Content-Type字段用于服务器回应时,告诉客户端,本次数据是什么格式。Content-Encoding 字段:
Content-Encoding字段说明数据的压缩方法。表示服务器返回的数据使用了什么压缩格式Keep-Alive字段:表明保持连接状态的时间等信息。
Set-Cookie字段:服务器返回缓存在客户端中的Cookie
Location:标识客户应该去哪提取文档
六、Http响应报文字段Content-type详解
Content-Type(内容类型),一般是指网页中存在的 Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件,这就是经常看到一些 PHP 网页点击的结果却是下载一个文件或一张图片的原因。
1 | Content-Type: text/html; charset=utf-8 |
常见的媒体格式类型如下:
- text/html : HTML格式
- text/plain :纯文本格式
- text/xml : XML格式
- image/gif :gif图片格式
- image/jpeg :jpg图片格式
- image/png:png图片格式
以application开头的媒体格式类型:
- application/xhtml+xml :XHTML格式
- application/xml: XML数据格式
- application/atom+xml :Atom XML聚合格式
- application/json: JSON数据格式
- application/pdf:pdf格式
- application/msword : Word文档格式
- application/octet-stream : 二进制流数据(如常见的文件下载)
- application/x-www-form-urlencoded :
另外一种常见的媒体格式是上传文件之时使用的:
- multipart/form-data : 需要在表单中进行文件上传时,就需要使用该格式
七、Http常见的状态码


八、实验:利用Cmd的telnet构造请求报文,向百度发送get请求
1、telnet www.baidu.com 80
2、按下Ctrl + ]
3、回车
4、输入
1 | GET /index.html HTTP/1.1 |
5、成功获得http响应报文
九、HTTP请求走私
1、产生原因
为了提升用户的浏览速度,提高使用体验,减轻服务器的负担,很多网站都用了CDN加速服务,最简单的加速服务,就是在源站的前面加上一个具有缓存功能的反向代理服务器,用户在请求某些静态资源时,直接从代理服务器中就可以获取到,不用再从源站所在服务器获取。这就有了一个很典型的拓扑结构

反向代理服务器与后端的源站服务器之间,会重用TCP链接,因为代理服务器与后端的源站服务器的IP地址是相对固定,不同用户的请求通过代理服务器与源站服务器建立链接,所以就顺理成章了
但是由于两者服务器的实现方式不同,如果用户提交模糊的请求可能代理服务器认为这是一个HTTP请求,然后将其转发给了后端的源站服务器,但源站服务器经过解析处理后,只认为其中的一部分为正常请求,剩下的那一部分就是走私的请求了,这就是HTTP走私请求的由来。
HTTP请求走私漏洞的原因是由于HTTP规范提供了两种不同方式来指定请求的结束位置,它们是Content-Length标头和Transfer-Encoding标头,Content-Length标头简单明了,它以字节为单位指定消息内容体的长度,例如:
1 | POST / HTTP/1.1 |
Transfer-Encoding标头用于指定消息体使用分块编码(Chunked Encode),也就是说消息报文由一个或多个数据块组成,每个数据块大小以字节为单位(十六进制表示) 衡量,后跟换行符,然后是块内容,最重要的是:整个消息体以大小为0的块结束,也就是说解析遇到0数据块就结束。如:
1 | POST / HTTP/1.1 |
其实理解起来真的很简单,相当于我发送请求,包含Content-Length,前端服务器解析后没有问题发送给后端服务器,但是我在请求时后面还包含了Transfer-Encoding,这样后端服务器进行解析便可执行我写在下面的一些命令,这样便可以绕过前端的waf。
2、四种常见走私请求
CL不为0的GET请求
假设前端代理服务器允许GET请求携带请求体,而后端服务器不允许GET请求携带请求体,它会直接忽略掉GET请求中的Content-Length头,不进行处理。这就有可能导致请求走私。
CL-CL
假设中间的代理服务器和后端的源站服务器在收到类似的请求时,都不会返回400错误,但是中间代理服务器按照第一个Content-Length的值对请求进行处理,而后端源站服务器按照第二个Content-Length的值进行处理,这样便有可能引发请求走私。
CL-TE
所谓CL-TE,就是当收到存在两个请求头的请求包时,前端代理服务器只处理Content-Length这一请求头,而后端服务器会遵守RFC2616的规定,忽略掉Content-Length,处理Transfer-Encoding这一请求头。
TE-CL
所谓TE-CL,就是当收到存在两个请求头的请求包时,前端代理服务器处理Transfer-Encoding这一请求头,而后端服务器处理Content-Length请求头。
十、CRLF注入
1、漏洞简介:
我对这个漏洞也不是特别了解,所以我还是看看基本定义和利用吧
CRLF是“回车+换行”(\r\n)的简称,其十六进制编码分别为0x0d和0x0a。在HTTP协议中,HTTP header与HTTP Body是用两个CRLF分隔的,浏览器就是根据这两个CRLF来取出HTTP内容并显示出来。所以,一旦我们能够控制HTTP消息头中的字符,注入一些恶意的换行,这样我们就能注入一些会话Cookie或者HTML代码。CRLF漏洞常出现在Location与Set-cookie消息头中。
2、漏洞复现:
(1)通过CRLF注入构造会话固定漏洞
固定会话漏洞:
如果注册前有一个session id为某个值,注册后发现自己的session id还是为这个值就极有可能存在固定会话漏洞
下面举一个固定会话漏洞利用的例子:
假如有一个网站,你注册了一个账号,注册之前抓包PHPSESSID = ghtwf01,注册成功后发现PHPSESSID依然为ghtwf01,此时是普通用户权限
这个时候就可以社工管理员点击某个链接,比如http://xxx/?PHPSESSID=ghtwf01,这个时候你的账户权限就会变为管理员权限(类似于CSRF)CRLF注入怎么构造会话固定漏洞呢?
构造链接:http://10.23.88.137%0aSet-Cookie:sessionid=ghtwf01
给管理员点击即可
(2)通过CRLF注入消息头引发反射型XSS漏洞
构造链接:http://10.23.88.137%0d%0a%0d%0a<script>alert(/xss/);</script>
3、修复方法:
只需过滤掉\r 、\n之类的换行符就可